BERT 모델을 한국어 맞춤형으로 제작한, KoBERT
이런 어려운 작업을 해주신 SKTBrain 팀에 박수를 보냅니다.
우선 BERT란 무엇인가?
간단하게 말하자면, 사전에 학습된 대용량 말뭉치 모델이라고 할 수 있습니다.
2018년에 위대한 구글에서 개발한 언어 모델인데, NLP 전반적인 분야에 아주 좋은 성능을 보여주는 모델이라고 합니다.
그리고 이런 BERT 모델을 한국어 기반으로 제작한 것이 바로 KoBERT 입니다.
KoBERT의 사용 방법에 대해서는 KoBERT Github에 간략히 소개되어있습니다.
https://github.com/SKTBrain/KoBERT
SKTBrain/KoBERT
Korean BERT pre-trained cased (KoBERT). Contribute to SKTBrain/KoBERT development by creating an account on GitHub.
github.com
하지만... 자연어 처리에 익숙치 않으신 분들이라면 저기 적혀있는 readme만 보시고 쉽게 쉽게 따라 하기는 어려울 수 있다고 생각합니다. 심지어 KoBERT가 만들어진지 몇 년 채 되지 않아서인지 구글링 해보아도 자료가 많지 않았고요.
그래서 어렵사리 직접 해보았습니다.
KoBERT를 이용해서 감성 분석 따라 해 봅시다.
☆ 시작하기에 앞서 ☆
> KoBERT에서 제공하는 여러 API 중 PyTorch를 사용합니다.
> 친절하게 Colab을 제공해주기 때문에 Colab을 사용합니다.
다만, 컴퓨터 사양이 괜찮으신 분들은 Colab에 들어가서 ipynb를 다운받으신 후 Jupyter Notebook에서 개발하셔도 무방합니다. 혹은 py 파일로 받으셔서 알맞게 코딩해주셔도 됩니다.
1. 데이터 준비
감성 분석을 위한 데이터가 준비되어야 합니다.
저는 포털 사이트의 뉴스 댓글의 감성을 분석하기 위해 약 75만 개의 댓글을 수집했고
약 1000개의 댓글에 수작업으로 감성 값을 레이블링 했습니다.
2. KoBERT 설치
지금부터 KoBERT Github의 내용을 참고하겠습니다.
https://github.com/SKTBrain/KoBERT
깃허브 내용대로 KoBERT를 설치해줍니다.

혹시 git을 잘 모르신다면

깃허브 좌측 상단의 Code 버튼을 눌러서 zip 파일을 다운로드하고 압축을 풀어도 됩니다.
zip 파일 다운로드받고 압축을 푸는 것이랑 git clone ~ 이랑 동일합니다.
pip install -r requirements.txt >> KoBERT 사용에 필요한 패키지를 설치해줍니다.
pip install . >> KoBERT를 설치합니다.
※ 주의 !!!
이때 설치 경로에 한글이 들어가 있으면 오류가 발생하기도 합니다.
가능하면 폴더명에 한글이 없는 곳에 설치해주세요.
(한글 경로로 인한 오류 내용)
https://tech-diary.tistory.com/26
3. Colab 설정

Open in Colab 버튼을 눌러서 Colab을 시작합니다.
깃허브 설명대로 [런타임] > [런타임 유형 변경] > 하드웨어 가속기(GPU)로 설정합니다.
이거 CPU로 하고 돌리면 엄청 느립니다....
그리고 GPU는 제한이 있습니다. 저 같은 경우에 12시간 가동하니 GPU랑 TPU 사용이 불가능해져서
결국 한 달 사용료 만원 정도 내고 계속 개발했습니다ㅠㅜ
4. 이제 Colab을 따라 해 봅시다.

위에서부터 하나하나 실행해주세요.
지금부터 변경해야 할 부분을 짚어보겠습니다. 나머지 구간은 그대로 실행해주시면 됩니다.
1) 데이터 파일 불러오기 + tsv 데이터 적용하기

!wget 명령어를 통해 파일을 다운로드하고
train data와 test data를 구분해주는 구간입니다.
이 부분 같은 경우에 저는 제 구글 드라이브에 데이터를 업로드하여 변형했습니다.
참고 : 구글 드라이브에서 내 파일 불러오기 >> https://tech-diary.tistory.com/29
구글 드라이브에 저장된 내 데이터 파일을 불러옵니다.
!wget "URL" -O dataname.tsv
그리고 저장한 이름 그대로 train data와 test data를 구분하여 저장합니다.
이때 tsv 파일의 형식에 따라 nlp.data.TSVDataset의 파라미터를 적절하게 구분해주어야 합니다.
참고 : 내 tsv 데이터에 맞게 TSVDataset() 설정하기 >> https://tech-diary.tistory.com/28
제 tsv 데이터에서는 0번 인덱스가 텍스트, 1번이 레이블이기 때문에 field_indices를 별도로 설정해주지 않았습니다.
field_indices의 기본값이 [0, 1] 입니다. 혹시 본인의 tsv 데이터에서 텍스트와 레이블의 인덱스가 0번, 1번이 아니라면, field_indices 를 별도로 설정해주셔야 합니다.
num_discard_samples은 tsv 데이터 상위 몇 개의 row를 제거할지 설정합니다.
제 데이터는 모든 row가 실제 데이터이기 때문에 별도로 설정해주지 않았습니다.
num_discard_samples의 기본값은 0입니다.

2) 파라미터 설정하기
기계 학습을 훈련시킬 때 필요한 파라미터를 설정할 수 있습니다.

max_len > 텍스트 데이터 최대 길이
num_epochs > 훈련 반복 횟수
필요에 따라 다른 변수들도 변경해주시면 되겠습니다.
3) Classification 개수 (분류 개수)
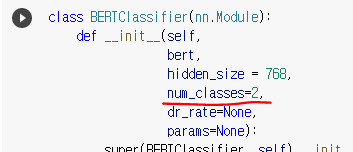
num_classes = 2 로 설정되어 있습니다. 2 가지로 분류하겠다는 뜻입니다.
저 또한 긍정 또는 부정의 감성 분류이기 때문에 2로 설정하였지만
혹시 다중 분류이신 분은 이 부분을 변경하시면 될 것 같습니다.
이렇게 필요한 부분을 본인의 데이터셋에 맞게 변경한 다음 계속 진행하시면 KoBERT 모델을 이용하여 본인의 데이터를 훈련시킬 수 있습니다.
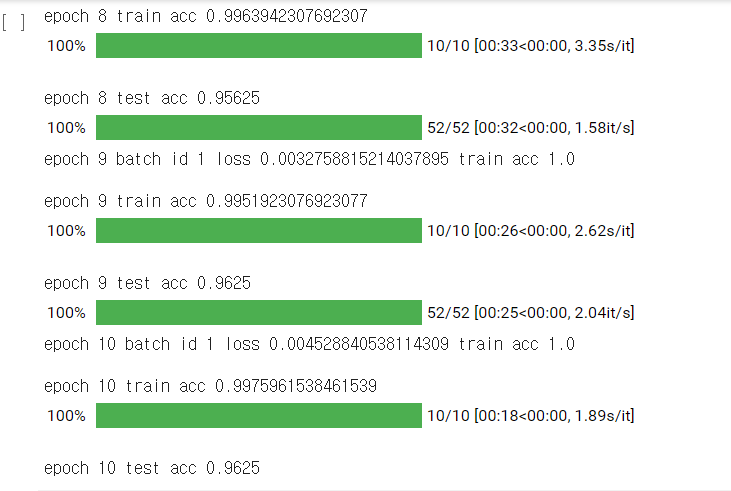
저는 epoch = 10으로 설정하였습니다.
훈련 데이터가 1000개로 매우 적은 수치였지만, 그래도 train accuracy가 0.99, test accuracy가 0.96으로 높은 수치가 나왔네요. loss 또한 0.005 이하이므로, 좋은 결과를 얻었다고 볼 수 있겠습니다.
4. 데이터 예측하기
자, 이제 훈련시키는 것까지 완료되었습니다.
그럼 이제 나머지 데이터에 적용해봐야겠죠?
KoBERT 모델을 활용하여 훈련시킨 모델을 불러서 새로운 데이터를 예측하는 방법입니다.
감성 값을 예측하는 함수를 만들어보겠습니다.
import pandas as pd
# 위에서 설정한 tok, max_len, batch_size, device를 그대로 입력
# comment : 예측하고자 하는 텍스트 데이터 리스트
def getSentimentValue(comment, tok, max_len, batch_size, device):
commnetslist = [] # 텍스트 데이터를 담을 리스트
emo_list = [] # 감성 값을 담을 리스트
for c in comment: # 모든 댓글
commnetslist.append( [c, 5] ) # [댓글, 임의의 양의 정수값] 설정
pdData = pd.DataFrame( commnetslist, columns = [['댓글', '감성']] )
pdData = pdData.values
test_set = BERTDataset(pdData, 0, 1, tok, max_len, True, False)
test_input = torch.utils.data.DataLoader(test_set, batch_size=batch_size, num_workers=5)
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(test_input):
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length= valid_length
# 이때, out이 예측 결과 리스트
out = model(token_ids, valid_length, segment_ids)
# e는 2가지 실수 값으로 구성된 리스트
# 0번 인덱스가 더 크면 부정, 긍정은 반대
for e in out:
if e[0]>e[1]: # 부정
value = 0
else: #긍정
value = 1
emo_list.append(value)
return emo_list # 텍스트 데이터에 1대1 매칭되는 감성값 리스트 반환input : 텍스트 데이터 리스트 외 KoBERT 설정 파라미터들
output : 입력한 텍스트 데이터 리스트와 1대 1 매칭 되는 감성 값 리스트
함수명이나 변수명을 댓글 데이터에 맞추어 작성했습니다.
본인의 데이터 도메인에 맞게 재구성하면 될 것 같습니다.
간단하게 KoBERT에서 제공하는 PyTorch API로 Colab에서 감성 분석을 해보았습니다.
잘못 설계하거나 설명에 오류가 있는 경우, 댓글로 지적해주시면 감사하겠습니다.
혹시 궁금하신 점이 있다면..
댓글로 남겨주시면 답글 달아드리겠습니다.
댓글 알림 자주 확인하니, 늦지않게 확인해볼게요...ㅎㅎ
'Python tech > NLP' 카테고리의 다른 글
| [KoBERT] nlp.data.TSVDataset() 적용하기 (0) | 2021.05.18 |
|---|---|
| [KoBERT 에러] TypeError: dropout(): argument 'input' (position 1) must be Tensor, not str 해결 방법 (0) | 2021.05.18 |
| [KoBERT 에러] Illegal byte sequence Error #42 해결 방법 (0) | 2021.05.18 |
| [Python] 단어 빈도 분석 + 워드 클라우드 (0) | 2021.02.08 |
| [Python] 감성 분석 결과 + 유의미한 차이인지 확인 (0) | 2021.02.07 |