특정 기간에서 사람들의 관심 주제를 알아보기위해 단어 빈도 분석을 진행합니다.
import nltk
# make noun frequency graph per religion
def make_top_word_graph( result, top ):
tokens = result.split(" ") # 문자열을 공백 기준으로 구분
text = nltk.Text(tokens) # nltk
topWord = text.vocab().most_common(top) # top n word
count = 30 # top word on graph
xlist = [a[0] for a in topWord[:count ]]
ylist = [a[1] for a in topWord[:count ]]
plt.figure(0)
font_name = font_manager.FontProperties(fname='./font/font.ttf', size=7).get_name()
rc('font', family=font_name) # 한글 적용
plt.xlabel('Word')
plt.xticks(rotation=70) # x축 라벨 회전
plt.ylabel('Count')
plt.title('keyword' +' TOP '+str(count)+' WORD')
plt.ylim([10, 33000]) # y축 범위 (최대값을 기준으로 동일하게 설정하기 위함)
plt.plot(xlist,ylist)
plt.savefig(result_path+'top-word-graph.png', dpi=400)
# make text file
make_top_file(topWord)위 코드는 TOP N개의 단어를 생성하고 그래프로 그려주는 함수입니다.
Python NLTK 라이브러리를 활용하여 쉽게 구할 수 있습니다.
이때 result 파라미터는 모든 단어를 공백을 기준으로 합친 하나의 문자열입니다.
KoNLPy를 활용하여 형태소 분석 진행 후, 명사만 추출하였으며
한 글자인 단어와 검색 키워드와 동일한 단어는 제외하였습니다.
마지막 make_top_file() 함수는 그래프 생성 이후, 텍스트 파일도 생성해주는 함수입니다.
def make_top_file(list): # make txt file
result_path = '../result/top-word/'
with open(result_path+"keyword-"+'top-word.txt', 'wt', encoding='utf-8') as f:
for l in list: f.write(l[0]+"/" +str(l[1])+"\n")
return 0
워드 클라우드 생성도 원하시면 아래 코드를 적용할 수 있습니다.
from wordcloud import WordCloud
# 워드 클라우드 생성
def make_wordcloud(text, title, num):
word_max = 100
wordcloud = WordCloud(font_path='./font/font.ttf', background_color='white',\
max_words=word_max, max_font_size=200, height=700, width=900).generate(text)
plt.figure(num) #이미지 사이즈 지정
plt.imshow(wordcloud, interpolation='lanczos') #이미지의 부드럽기 정도
plt.axis('off') #x y 축 숫자 제거
plt.savefig('../resul/word-cloud/'+title+'-wordcloud.png', dpi=300)
wordCloud 라이브러리를 통해 쉽게 생성할 수 있습니다.
- background_color : 배경 색
- max_words : 최대 단어 개수
- max_font_size : 최대 단어 크기
위 코드를 통해 생성된 결과입니다.
단어 빈도 분석 그래프
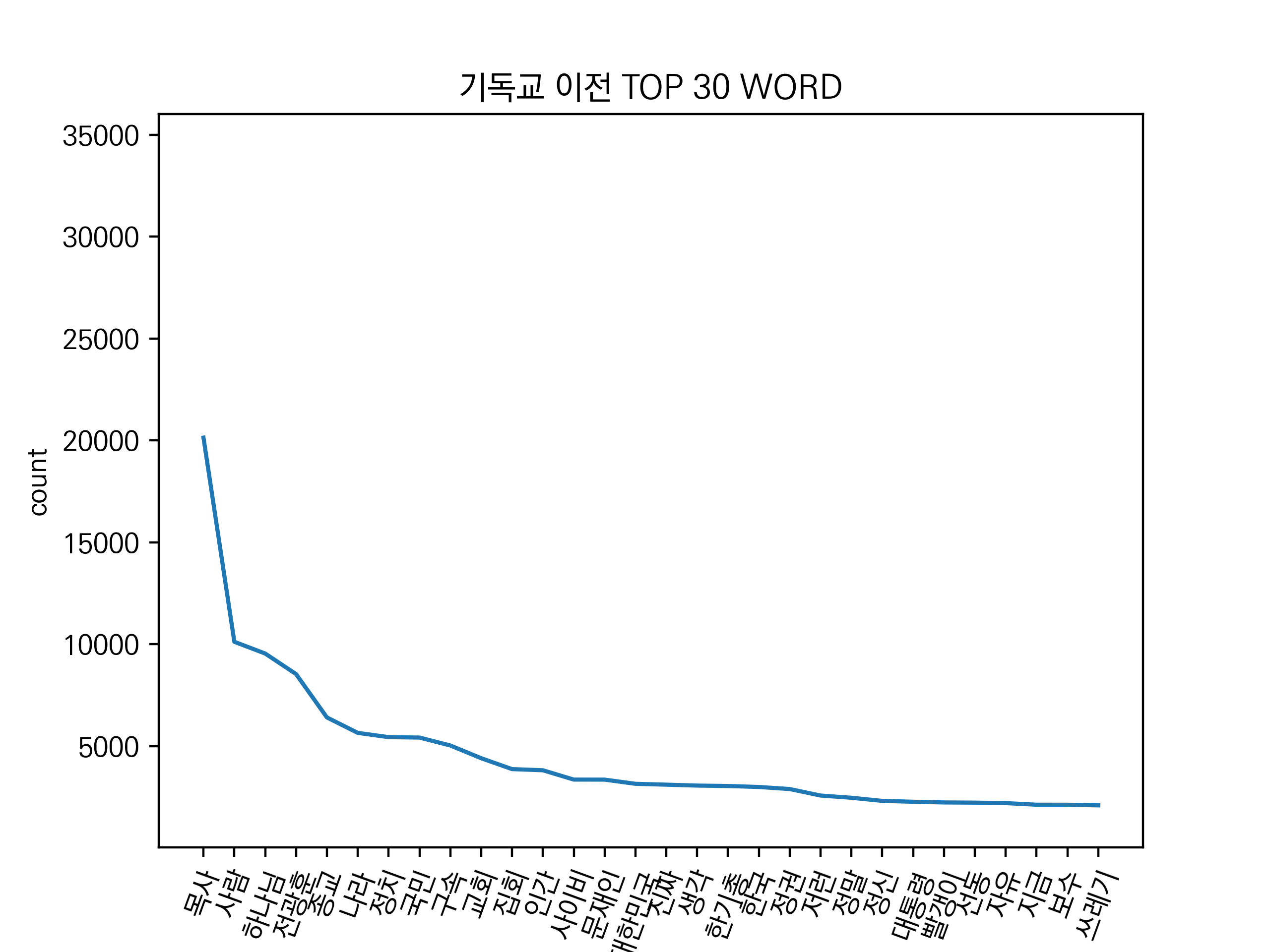
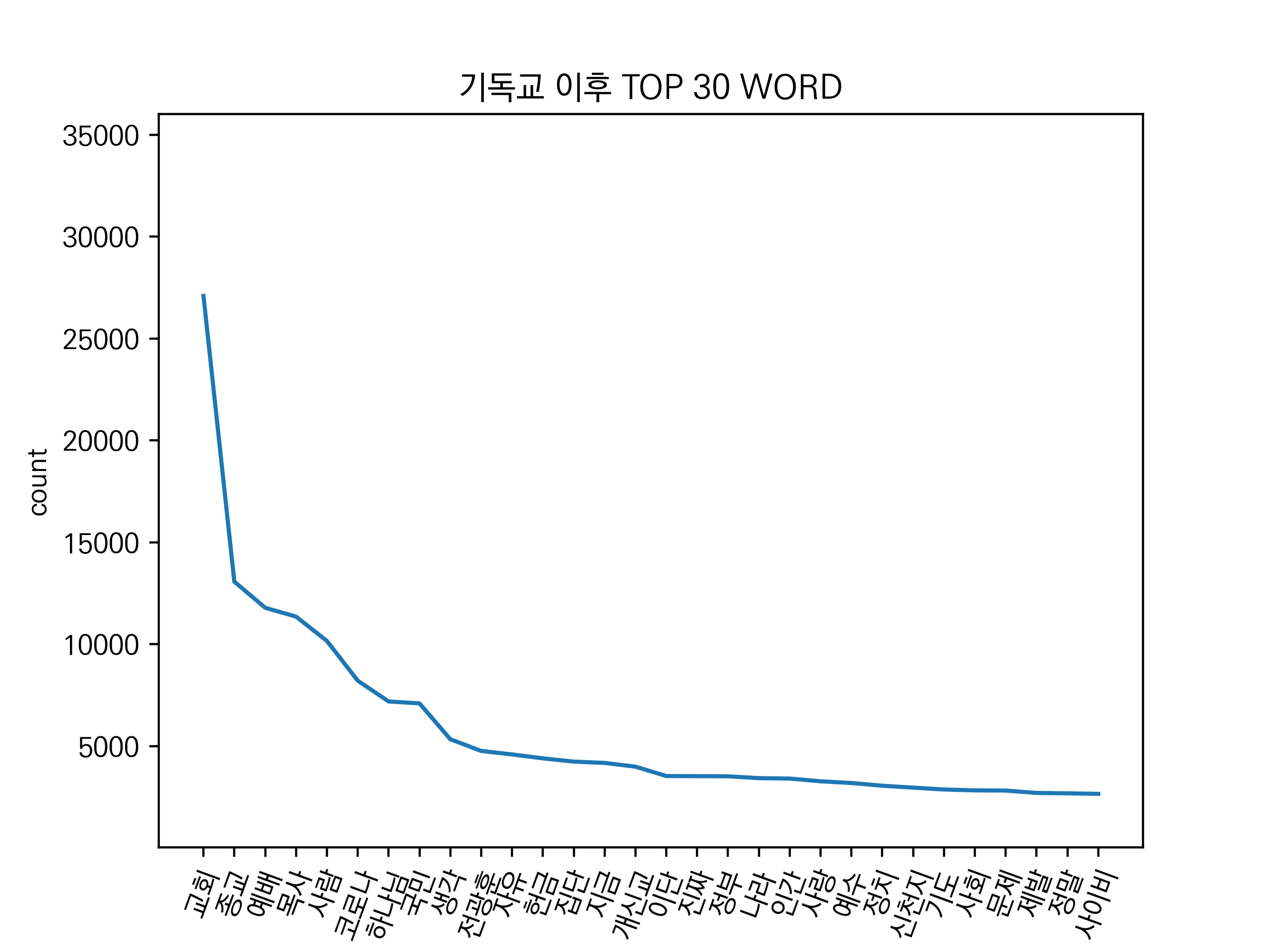
'기독교' 키워드의 코로나19 전/후 그래프입니다.
이전에는 특정 직업이나 인물과 관련된 단어 빈도가 많았고, 정치와 관련된 단어 수도 많았습니다.
하지만 이후에서는 정치와 관련된 단어는 줄어들었고, 코로나19 혹은 집단 감염과 관련된 단어 빈도가 증가했습니다.
더 많은 그래프를 확인해보고 싶다면 아래 Github에서 보실 수 있습니다.
github.com/Minku-Koo/Comment-Sentiment-Analysis
워드 클라우드
워드 클라우드 생성 결과입니다


위 단어 빈도 그래프를 그대로 워드 클라우드로 표현한 모습입니다.
마찬가지로 더 많은 워드클라우드 정보는 깃허브에 업로드 해두었습니다.
단어 빈도 분석 - 텍스트 파일

단어 빈도 분석을 하면서
그래프와 워드 클라우드를 생성해보았습니다.
텍스트 마이닝의 가장 간단한 방법 중 하나로서, 다양한 분석이 가능하겠습니다.
감사합니다.
'Python tech > NLP' 카테고리의 다른 글
| [KoBERT 에러] TypeError: dropout(): argument 'input' (position 1) must be Tensor, not str 해결 방법 (0) | 2021.05.18 |
|---|---|
| [KoBERT 에러] Illegal byte sequence Error #42 해결 방법 (0) | 2021.05.18 |
| [Python] 감성 분석 결과 + 유의미한 차이인지 확인 (0) | 2021.02.07 |
| [Python, keras] 딥러닝을 활용한 감성 예측 + 그래프 생성(plot) (0) | 2021.02.07 |
| [Python keras] 감성 분석 딥러닝 모델 생성 - TextVectorization (0) | 2021.02.01 |