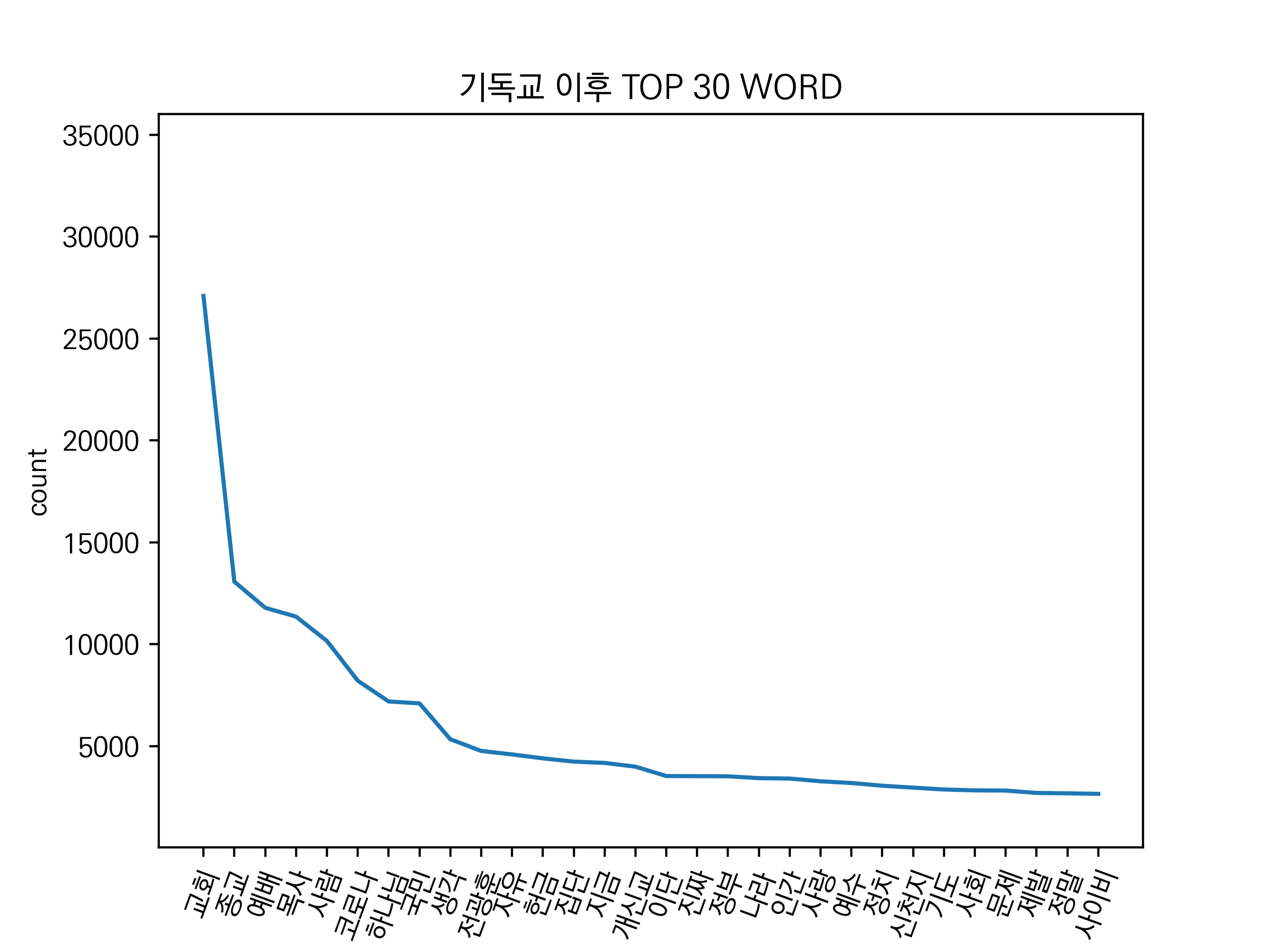
특정 기간에서 사람들의 관심 주제를 알아보기위해 단어 빈도 분석을 진행합니다. import nltk # make noun frequency graph per religion def make_top_word_graph( result, top ): tokens = result.split(" ") # 문자열을 공백 기준으로 구분 text = nltk.Text(tokens) # nltk topWord = text.vocab().most_common(top) # top n word count = 30 # top word on graph xlist = [a[0] for a in topWord[:count ]] ylist = [a[1] for a in topWord[:count ]] plt.figure(0) font..